Problem
SAP HANA workloads emit rich session, statement, and wait telemetry. In practice, operators still face alert fatigue, slow mean-time-to-diagnose, and governance risk when someone acts on a half-formed theory.
The goal is not an unconstrained auto-remediation bot. It is a governed triage assistant that turns signals into ranked hypotheses, bounded actions, explicit approvals where impact is high, rollback where defined, and an append-style audit trail.
Constraints
- Core detection, ranking, and action eligibility stay deterministic or rule-driven; no LLM as sole authority for root cause or safety.
- Remediations are allowlist-only (`config/action_allowlist.yaml`); high-risk paths require human approval and rollback hooks.
- Secrets and HANA connectivity via `.env` / BTP destinations—never committed; synthetic CSV fixtures for local regression.
- Evaluation is offline and honest: synthetic incidents, rubric-based narrative scoring, no claim of production representativeness without evidence.
End-to-end pipeline
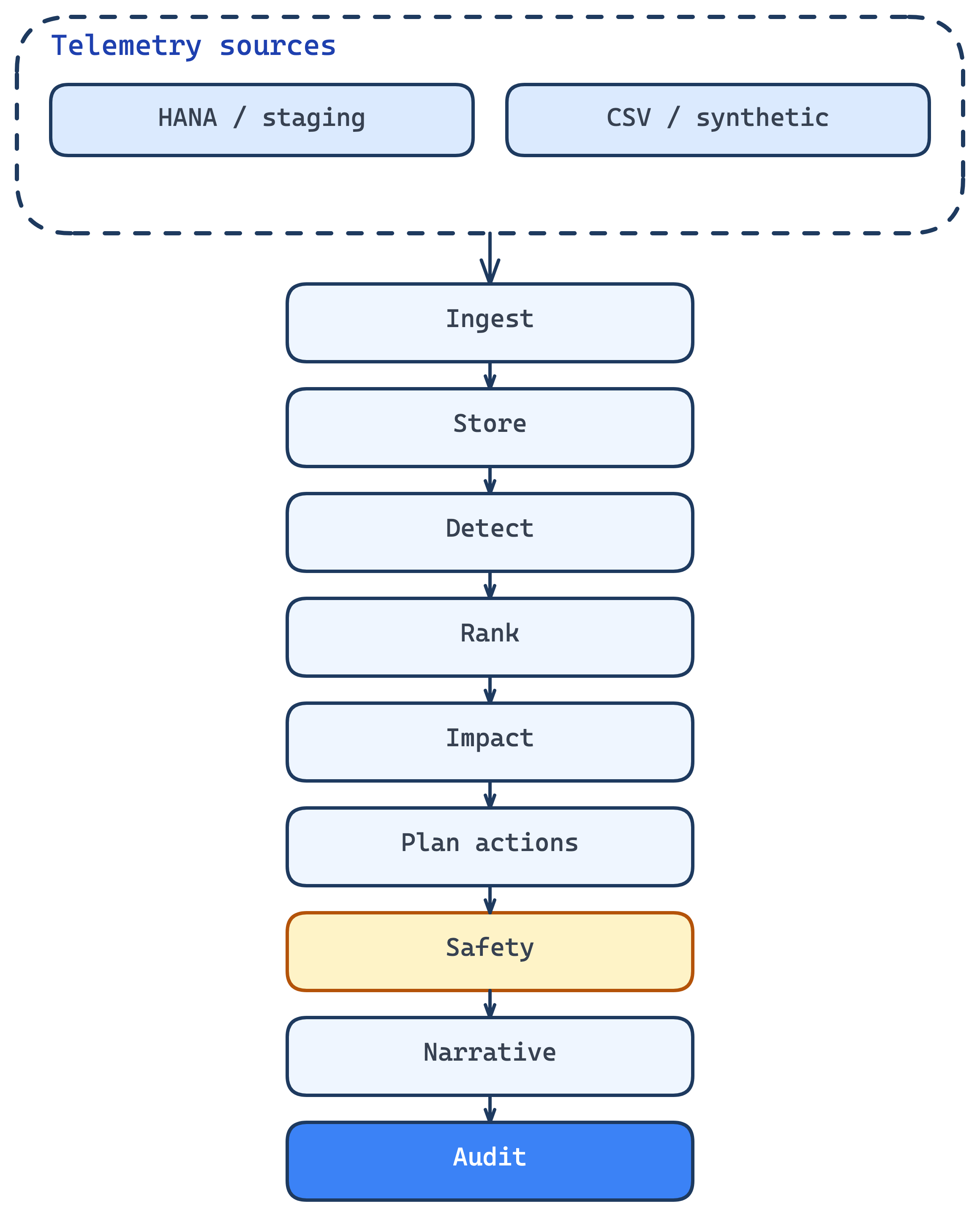
Mirrors package layout in the triage repo: ingest through audit, with safety and human approval on the critical path before narrative and logging.
Key technical decisions
- Package boundaries mirror the pipeline: `ingest`, `detector`, `reasoner`, `impact`, `actions`, `safety`, `reporter`, `audit`—so the story matches the code layout.
- Hybrid rules + confidence for `rank` and `impact` (Phase 6) instead of LLM-first diagnosis; reduces brittle “model guessed the cause” failure modes.
- Template-first narrative (`what / why / so what / now what`); optional model only polishes wording, not facts or eligibility.
- Eval harness (`scripts/eval_run.py`) forces LLM explainer off by default for reproducible CI-style gates on triage quality and safety metrics.
Security & governance
Allowlist violations target zero in aggregate metrics. High-risk actions hit an approval gate; rollback manager exercises stubbed paths under eval. Audit logs correlate decisions to `incident_id`.
Risks like narrative hallucination misread as ground truth are mitigated by template-first output, labeling model-assisted sections when enabled, and keeping ranked causes tied to SQL feature evidence.
Stale or unreachable HANA reads: block or degrade auto-execute, surface errors to operators, and record failures in audit (see architecture failure-mode table).
Evaluation & metrics
Seven offline metrics on fixed CSV + regression YAML (see `docs/evaluation-metrics.md`). Baseline vs v2 profiles (e.g. alert dedup) ship to `reports/eval-baseline-vs-v2.md`.
- MTTD proxy
Symptom onset → first alert (minutes); lower is better; report-only target.
- Precision@k (root cause)
Expected hypothesis in top-k; k=1 and k=3 reported.
- False alert rate
On negative cases, fraction with alerts; target 0 on fixture-defined negatives.
- Allowlist violation rate
Any proposed action not in allowlist; target 0.
- Narrative completeness
Rubric over required markdown sections + template version footer; target 1.0 on synthetic run.
- Rollback success rate
RollbackManager returns expected status for proposed actions.
- Human approval latency (simulated)
Mean simulated seconds from regression YAML; report-only.
What I'd change next
Tighten the loop between detector YAML thresholds and fixture-defined alert rules so eval stories and dashboard thresholds never diverge silently.
Add a second eval mode that replays production-shaped traces once we have consenting staging data—keeping synthetic gates for regression, adding realism checks separately.
Wire optional SAP AI Core / Cloud SDK AI only behind explicit policy objects and destination binding, with cost and latency caps per incident class.
Repository
Public source: triage pipeline, docs, and offline eval harness.
GitHub